
LLMs, like the ones behind ChatGPT or Gemini, have two big weaknesses:
- Their knowledge is frozen at training time (“knowledge cutoff”)
- They can “hallucinate” or confidently make things up
Retrieval-Augmented Generation (RAG) is a pattern that fixes both problems by giving an LLM access to the right data at answer time. Instead of asking the model to “remember everything”, RAG lets it look things up first, then answer.
Core idea
RAG = search for relevant documents → feed them into the LLM → have the LLM respond using (also) those documents.
So instead of:
Chat, tell me everything you know about X.
we do:
Chat, here are a few documents about X. Read them and answer my question based on (or prioritizing) these.
Vanilla LLM vs RAG-enchanced
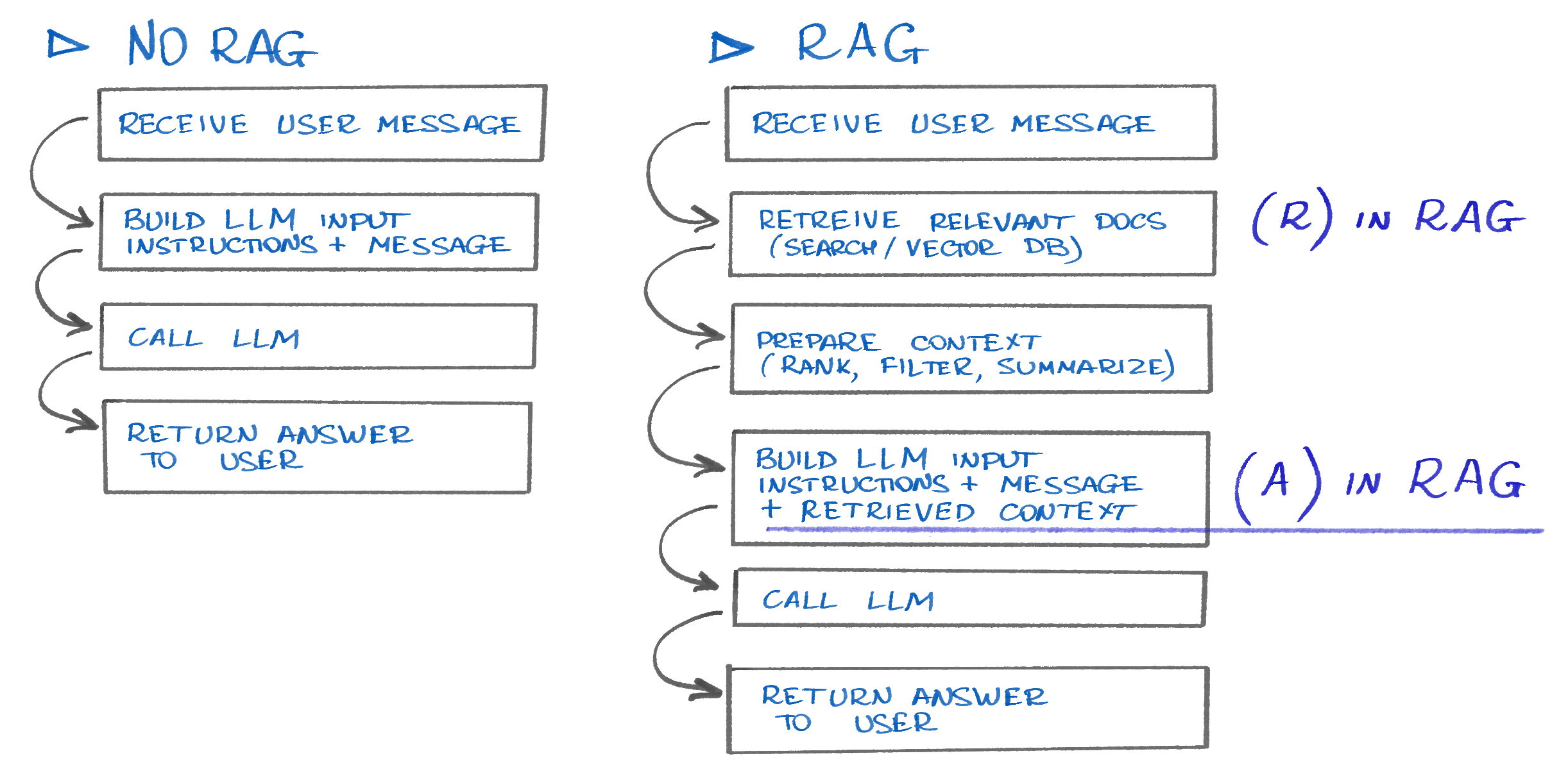
The key additions are:
- Retrieval of the relevant information
- Augmentation of the LLM input with the new information (context). Think of it as adding the extra info to the prompts for the model to review before answering.
RAG step by step
Imagine you’ve built a RAG system over your company’s documentation.
- User asks a question
How do I integrate your API with Python? - Embed and documents
- The question is converted into a vector (embedding).
- A vector database (like Pinecone, Weaviate, pgvector, etc.) finds the most similar docs:
- “Python SDK quickstart”
- “Authentication with API keys”
- “Error handling examples”
- “Monitoring guidelines”
- Build a prompt with context
The system assembles a prompt roughly like:You are a helpful API integration assistant. Use only the information in the context below.
Context:- Doc 1: …
- Doc 2: …
- Doc 3: …
Answer this question: How do I integrate your API with Python?
Note 1. RAG systems add retrieved text into the prompt, but usually only after a bunch of extra processing. Also, some newer architectures inject retrieval inside the model layers rather than as plain text, but that’s not what you would typically use via normal APIs.
Note 2. The model never “stores” this information in its weights, it just attends to those tokens during this one call and then forgets them.
Note 3. In real systems, there’s usually a bit more happening between retrieval and the final prompt than just “take the top-k and paste it in”. That “middle layer” can be quite sophisticated, but it’s outside the scope of this post.
- LLM generates an answer
The LLM reads the question and the retrieved docs, and produces an answer grounded in that context.
Where does the extra data come from?
RAG is very flexible about what you retrieve:
- Product manuals, customer support and technical docs
- Internal wikis (Confluence, Notion, Google Docs)
- Knowledge bases, tickets, emails
- Databases (after pre-processing into text chunks)
- Websites (after crawling & cleaning)
- Whatever source your team can connect to
Why RAG is a good thing
1. Up-to-date answers
You can add or update documents without retraining the model. Retraining is expensive, requires people with the right expertise, and adds extra time for everything around the training process.
New docs → re-index → system knows about them immediately.
2. Domain-specific expertise
The base model doesn’t know your internal policies or APIs.
RAG lets you “teach” it from your own knowledge base at runtime.
3. Fewer hallucinations (if done properly)
Because the model is instructed to use provided context, it tends to stay closer to the truth.
⚠️ You still need good prompts and guardrails.
4. Cheaper and easier than fine-tuning
In many cases, RAG gives more value per €/$/₴ than fine-tuning, especially for Q&A and support use-cases.
When RAG is not the solution
RAG can struggle when:
- You need the model to learn a new style or format deeply. Example: writing in a very specific brand voice – here fine-tuning may help better.
- The data is very small and rarely updated. Simple prompt engineering (“add it directly to the prompt”) may be enough.
- You require complex reasoning across many documents and long chains of logic. Better options are to combine RAG with tools like agents, function calling, or intermediate reasoning steps (Chain -of-thought or CoT prompting approach).
RAG isn’t some mysterious magic trick, it is all about teaching a model to look things up before it speaks. Once you see that, LLMs stop being black boxes 🧞 and start looking like tools you can reason about, design around, and actually trust.
If this made sense to you, consider wiring up a small RAG demo, poke at the prompts, break it, fix it, and watch how the behavior changes. The more you experiment, the less intimidating this whole “AI” thing becomes. And the more ideas you’ll have for using it in your work.


