
A 1M context window is great – if you treat it as a tool, not a target.
In practice, almost every long thread I’ve let bloat would have been better as two or three short, deliberate ones. The headroom isn’t there for you to fill – it’s there for the rare case when the work genuinely won’t fit.
Last Tuesday I was 550K tokens into a thread about our skills builder when Claude proposed a fix I’d already tried, in the same chat, an hour earlier. I closed the tab, pasted five file paths and a six-line state.md into a fresh chat and asked the same question. The answer came back in half the time and was, if anything, better. Same model, same week, same work. Different desk.
The chat is working memory you rent by the token, every turn.
What “context” actually is
The context window is the total pool of tokens the model can see at once during a single request. It holds everything:
- The system prompt (instructions, tool definitions, your CLAUDE.md, memory)
- The full conversation history – every message you sent, every response the model gave
- Tool calls and their results (file reads, command output, search hits)
A token is roughly ¾ of a word, or about four characters. And here’s the bit that surprised me: the model is stateless between requests. It doesn’t “remember” the chat on its own. The harness (Claude Code, in my case) replays the entire transcript on every single turn – so as your chat grows, the cost of each new turn grows with it.
1M, in practice
A 1M context is like a bigger desk, not a smarter brain. Same model, just more room to spread paper out – and a bigger desk doesn’t help you think if most of the paper on it is stale.
The standard Claude context is 200K. The 1M variant (for example claude-opus-4-7[1m]) is 5× larger – roughly 750,000 words, or several large books’ worth of text. You can hold a very large codebase, long conversations, and many big file reads in working memory at once without losing the earlier parts.
And there’s the trap: capacity as a target.
Yes, a long context costs you more 💸
Opus 4.7 (at time of writing) is $5 per million input tokens and $25 per million output tokens. That rate is flat across the full 1M window – a 900K request is billed at the same per-token rate as a 9K one. No cliff at 200K, no long-context surcharge. (That used to be a thing on older Claude models, and I’d half-remembered it as still applying. It doesn’t.)
So the cost story is straightforward: the whole context is re-sent on every turn, and you pay per token of it. A turn at 800K input costs roughly 4× a turn at 200K.
Prompt caching softens it. The stable prefix of the context (system prompt, earlier turns) can be cached, and cache reads run at $0.50 / MTok – 10% of the input price. So an 800K context isn’t all charged at full rate every turn; the unchanged parts hit the cache. The cache doesn’t hold forever, though: entries have a 5-minute TTL by default (a 1-hour option exists at a higher write cost), so a long idle gap means a cache miss and a full re-charge on the next turn.
When the harness compacts behind you
When a chat approaches the window limit, the harness runs compaction: it summarises the older parts of the transcript and starts a fresh window seeded with that summary.
- It’s lossy. The gist survives; exact file contents, line numbers, and precise tool output don’t.
- It costs tokens. The summary is itself a model call over the large context.
- It breaks the cache. The fresh window no longer matches the cached prefix, so the next turn is charged closer to full rate.
- You don’t have to wait for it. Starting a new chat at a natural boundary is usually cleaner and cheaper than letting a thread balloon until the harness compacts it behind you.
When I start fresh, and when I keep going
I start a new chat when:
- I’m switching to an unrelated task. A bug fix in the auth module and a new UI feature share almost nothing. Carrying the first into the second is just paying to re-send irrelevant tokens.
- The thread is long and the early context no longer matters. If the last 30 turns are about a problem I already solved, I’m paying to re-read history the model no longer needs on every new turn.
- The chat has gotten confused or off-track. In one long planning thread, the model started arguing for a design we’d already talked through and ruled out about thirty messages earlier. Compaction had quietly blurred that detail away, and I was arguing with a model that no longer had the receipts.
- I just finished a discrete unit of work – a PR merged, a bug closed, a question answered. Natural stopping point.
I keep the chat going when:
- The work is genuinely continuous and the history still matters. Last week I did a multi-step refactor across six files, with the model holding the architectural decisions in working memory the whole way through. Resetting in the middle would have cost me an hour of re-grounding. That chat earned its tokens.
- I’m mid-investigation and the model has built up an understanding of the codebase I’d lose by resetting.
How to start a fresh chat well
Don’t just dump yourself back to zero. Carry forward the minimum that matters:
- A one-paragraph restatement of the goal and current state
- Pointers to the relevant files (paths, not full contents – the model can re-read on demand)
- Any decisions already made that shouldn’t be relitigated
Durable artefacts (CLAUDE.md, a design doc, a tracking ticket, project memory) are the right home for anything that should survive across chats. I’ve come to treat the chat as scratch space, and the artefacts as the record.
/context: see what you’re actually paying for
Before reaching for any of those levers, the most useful command in Claude Code is the one that lets you look inside your window: /context.
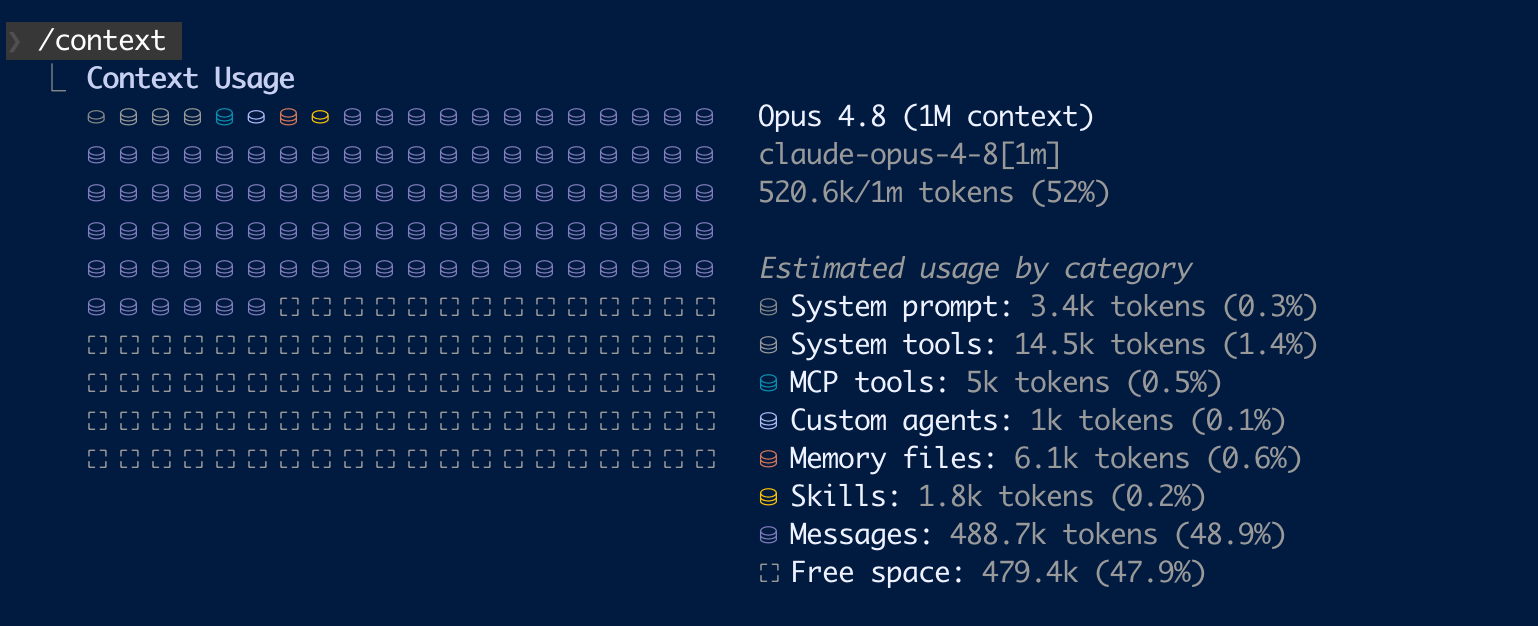 528.6K of 1M used (52%). Messages alone: 488.7K – 92% of everything currently in the window.
528.6K of 1M used (52%). Messages alone: 488.7K – 92% of everything currently in the window.
That’s a real session. The headline number (52% full) isn’t the interesting bit – the breakdown is: messages alone account for 488.7K, while everything else combined (system prompt, system tools, MCP tools, custom agents, memory files, skills) comes to about 32K, under 6% of what’s used.
Drill in and you see exactly what’s loaded. MCP tools, on-demand:
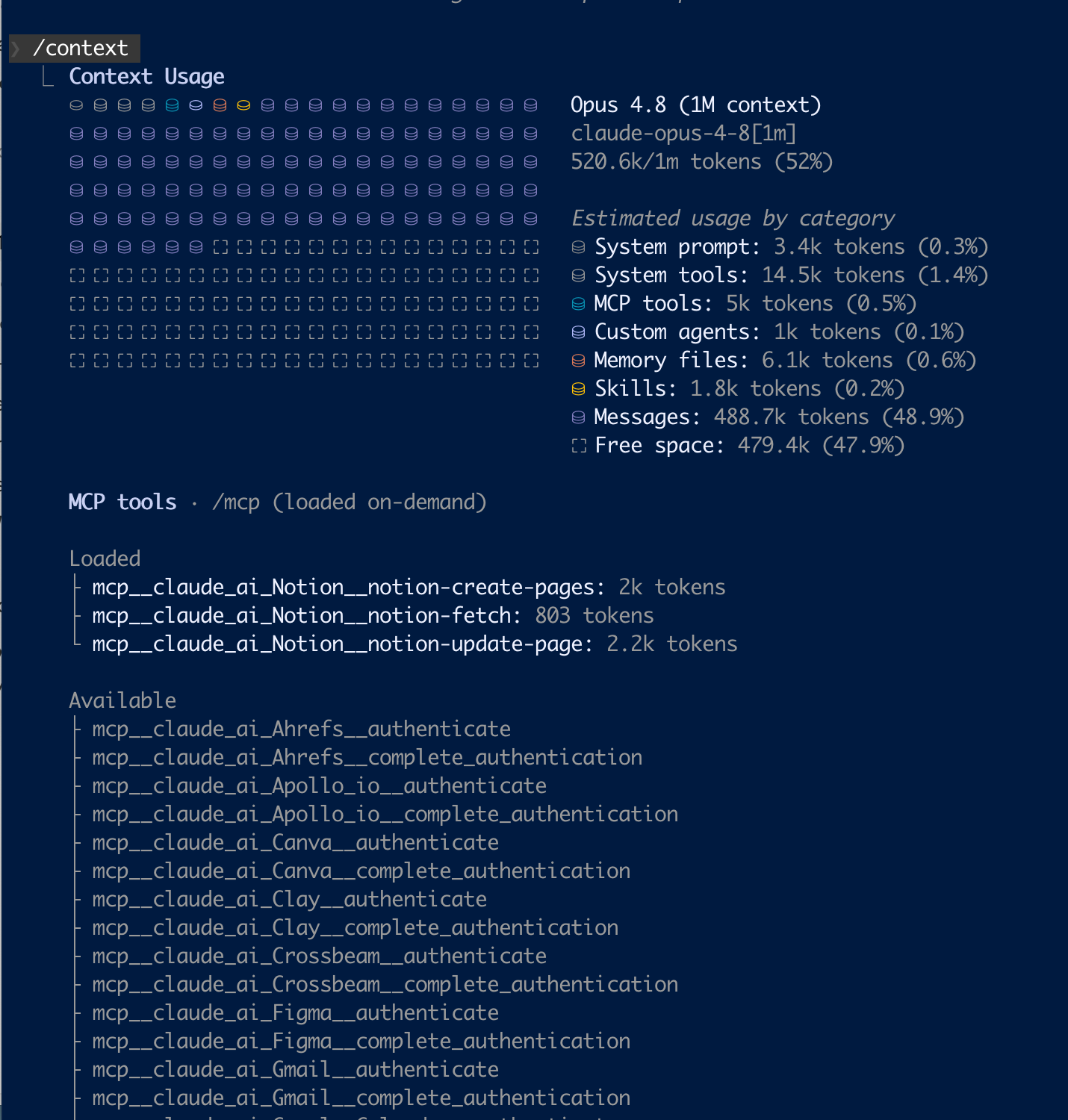 Three Notion tools loaded (~5K). The “Available” list (Ahrefs, Apollo, Canva, Clay, Crossbeam, Figma, Gmail…) costs zero until something actually loads it.
Three Notion tools loaded (~5K). The “Available” list (Ahrefs, Apollo, Canva, Clay, Crossbeam, Figma, Gmail…) costs zero until something actually loads it.
Agents, memory files, skills:
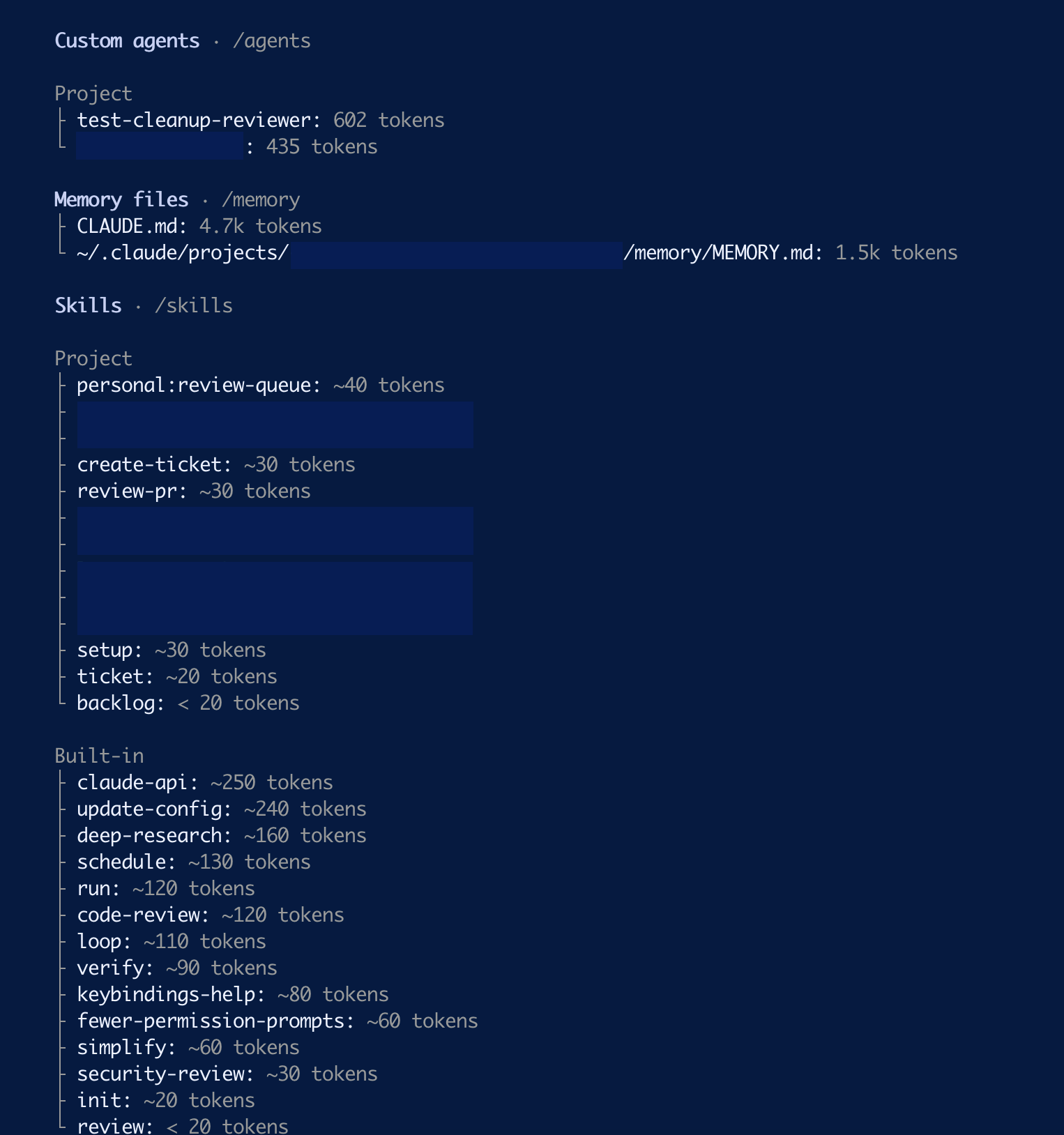 Custom agents and project skills, with their per-item token cost.
Custom agents and project skills, with their per-item token cost.
A few things /context changed for me:
- The chat is almost the whole bill. If 90%+ of your used window is
Messages, the answer isn’t to trim your skills config or prune MCP tools. It’s/clearor/compact. - MCP tools cost less than I feared. I’d half-expected my Notion/Figma/Apollo setup to be quietly eating tens of thousands of tokens. Loaded set this session: ~5K. Everything in “Available” but not loaded is free.
- Memory files are right where you set them. CLAUDE.md (4.7K) + MEMORY.md (1.5K) ≈ 6K every turn, forever. Cheap, but it does set a floor.
- Custom agents and skills are quietly steady. ~1K and ~2K respectively here. Worth knowing once, not worth tuning.
Look first. Then trim, or clear.
What to actually do in Claude Code
A few practical levers I use day to day.
/clear– the reset button. All-or-nothing: the model’s working understanding of the code disappears with the transcript, and you’ll pay to rebuild it. The right lever at the natural stopping points above; the wrong one mid-refactor./compact– compaction on my terms, before the harness does it at the ceiling. Same costs as the section above – lossy, not free, breaks the cache. On a chat that’s still small, it spends tokens to make the context worse.- Keep a
state.md. For work that will span multiple chats: goal, decisions so far, file paths, open questions. Starting fresh then takes one paste – exactly that file made the 550K reset at the top of this post painless. (More on this pattern, scaled up to multi-agent work, in STATUS.md: a shared file for multi-agent work.) - Watch what you let in. Big file reads, long tool outputs, log dumps – they stay in the context for the rest of the chat. If I only need a glance at a 50K-line file, I narrow the read rather than carry the whole thing forward at full price.
The way I think about it
Context is working memory you rent by the token, every turn. Keep in it what the current task needs, and no more. Push anything that has to outlive the task into files. Start fresh when the task changes, or when the history stops earning its cost.
The 550K thread I opened with: the state.md that made resetting painless was six lines. The 1M window is a ceiling, not a target. Most of the time, the best thing you can do with it is leave most of it empty.
Thanks for reading!